Note: This is not meant to be a tutorial or a guide, it’s more a story of my journey while building something. A story in which I will try to show the decisions that I made and why I made them. Talk about errors I encountered and the unknowns that caused me problems. In case you want to make a decision based on this post, I would highly suggest you first do your own research, and also talk to people with way more experience than me.
If you don’t want to read the rest of the post, you can check the code directly in those 2 repositories:
Since the days that I started to learn more intermediate things about computers and programming, I was finding it hard to think of projects or ideas that could help with my learning, or at least I thought I did.
Ideas like hangman or tic-tac-toe seemed basic. Good for learning and experimenting with the syntax of a new language, but nothing worth doing for anything more complex. On the other side, ideas like building your own programming language, a new text editor, or a fancy game engine seemed too much. There was something else as well, the need to build something that someone would find useful, while learning something new. That new fancy library that people would start using, the new application that would help people in their daily lives, or that small service that would provide me with some money on the side.
Building something useless, I partly saw as a waste of time. Building something useful, well, you needed a good idea first, and most ideas I had either were already done or had alternatives that would take me years to even get near at.
After some time I saw that searching for what I considered a useful idea takes time, or even worse just waiting for it was the waste of time I was trying to avoid in the first place. Similarly as spending minutes trying to decide which Netflix TV show to watch, I had many options which I went through time and time again but never really could decide on the ‘best’ one. The useful one.
I had to start making something, so what I did is shift my mind to look at those projects and ideas differently. Deciding to build something ‘useless’ until a useful idea came to mind, and I thought of doing it mainly to learn and experiment with new things. This allowed me to do things backwards, instead of using a tool because it was the best one for a feature or service, I was deciding which features to add because of the tools I wanted to use.
Thinking about it like this allows adding complexity to even simple ideas as a hangman game. An idea as vague as ‘building your own text editor’, can become a really interesting project, providing a good experience to learn multiple new tools.
As an example, I wanted to use Go, a lot of AWS services, and learn more about deploying and maintaining my applications in multiple environments. Also use some tools like Redis and RabbitMQ, to allow me to learn more about them.
I didn’t decide to build a text editor though, yet, but something similar. Similar in the sense that it already existed, and no one would probably use it.
What is it called?
The name is ‘tomorr’. Tomorr is a famous mountain in Albania, a beautiful country with an interesting history, and amazing people. In this case, tomorr will represent an application that is over-engineered, a little bit expensive to run, and not the best solution to the problem it desires to ‘fix’.
The problem, and the solution
Like a lot of other people, I enjoy listening to music, and I’m interested to know when an artist I like releases a new track or album. Now if you follow them on social media, you’ll probably just get that, but that approach does not work for me. I don’t use social media quite a lot, and even those social media sites I do use, I mostly use to follow tech-related stuff.
If there’s something that I check daily, and try not to miss any notifications from it, it’s my email. So I thought it would be great if I could know by email when an artist I like releases something new.
I decided to use Spotify and its API to solve this problem. As you know Spotify already provides notifications, and the ‘bell’ once you enter the app, where you can see if anyone you follow released a new track or album. The bell is great, but those other notifications do not work for me. I never received a notification by email, so I continued to make my own solution.
The API provides information about artists, albums, and each track, so using this data from Spotify, I thought of a solution that would work well enough, with a few flaws.
The idea was to have a list of artists that we want to get notifications from, query them and their albums when we first follow them and store the artist itself and the album ids on a database. After this initial step is finished, a scheduler then would get followed artists from the database, and query them again. If we find that the number of the albums for the queried artist is equal to the number of albums we have in the database for the same artist, we don’t do anything. However when the album count from the Spotify API response is bigger than our album count in the database, we then compare the albums from the response, with the ones we have in the database, and once we find the new one, we send an email to the users that followed the artist that made this release.
Let’s assume that Spotify would allow us to send around 300 requests per minute. If we had only a few followed artists, we would be quite fast to notify the users about new releases, but once the number of artists increased, the delay for the notifications by tomorr would increase as well. Having 10000 followed artists in the application would mean that each one of them would have to be queried at least once before we start the process again, and with 300 requests per minute, we would have delays.
Since this was supposed to be a project purely for learning purposes, this was not a very big problem for me.
You can see that it is not a very complex solution, and it could probably be done with a small Python application, and an instance of MongoDB, but I wanted to take it to the next level.
I was learning Go at the time and thought of this as a perfect time to use it. I had been reading and researching about microservices a lot too and wanted to build tomorr using that architecture. This is the age of microservices, why the hell would I start with a monolith?
Except for Go and microservices, it had been a few weeks since I was messing with AWS. Enjoying the experience, I thought after finishing the application, I would deploy it there. It would be a perfect way to get more hands-on experience with something that would be similar to what a ‘real-life’ application is.
Couldn’t stop there of course, so I added Redis, RabbitMQ, ElasticSearch, and some small things that I did not have a lot of experience with at the time.
While writing the idea, drawing the architecture, and taking notes on the technologies I wanted to use, I saw myself falling back to a feeling experienced many times before. Getting all excited about the idea, the architecture, and the tools to be used while building it, and then feeling overwhelmed some days later, because being hit with errors and unknowns every minute can become quite tiring. Wanting to continue and build this until the end, I cut off some of the new tools and decided to keep only those that I really wanted to learn at the time.
I switched to a language that I was more familiar with, instead of Go. I could always rewrite the application in Go later if I wanted to.
Microservices architecture required me to add about 2-3 new services, so I switched to a monolith. Here as well the possibility to split up the application later and add new services was always present. Thinking about it now, why would you start with microservices for a simple application, what the hell was I thinking?
Building tomorr
The backbone
The first days of tomorr were easy, a big part of this time had to do with the setup of the structure and main libraries planned to be used. Java 17 and Spring Boot were chosen for the backend, mostly because of my familiarity with Spring Boot and the way it is configured. Here I had a decision to make, use Spring Web or Spring Webflux. For this project, I would not take the word ‘overkill’ too seriously, but when it came to Weblflux an exception was made. I like reactive programming, and understand its use cases, but the complexity it adds was not something that I wanted to deal with in tomorr.
With the main backend library out of the way, the other decision was on the structure. From the early days of my programming journey, the way that people decided on the structure of their application always interested me. Every time I start learning a new language or framework, one of the first things to search is ‘how do you structure an app in x?’. In my mind, this is one of the most important parts, and seeking the ‘perfect’ structure was worth it. As you know, we are only one Google search away from finding what people think ‘perfect’ is, but even when we do, we find multiple different definitions of it. When it comes to the project structure, specifically in Java, you will find most people will support the idea to either structure by feature, by layer, or a mix of the two.
My experience in projects that are packaged by layer showed me that the result is not pretty once there are many classes. It’s easy to find stuff once you get used to it, but you can end up with packages that have 50+ classes in them. Because of reasons like this, packaging by feature seems a little better, but for tomorr the decision was to use a mixed structure.
The features, like the part of the application that does syncing, that deals with users, or the one handling albums, were all packaged by feature. Configurations, utility classes, properties, and the API layer itself were packaged by layer. This mix of both ideas can probably be a little confusing at first, but in my opinion it is quite easy to get used to and expand a little. tomorr was not going to be a big project, so this structure fits well here, but I’m not sure if it would be ideal for a project with more code.
Data
Once the structure was dealt with, there was the issue of data. Thinking about using a NoSQL database for tomorr was not the right approach. The data in tomorr had both structure and relations, an SQL database like Postgres fit perfectly here.
The next step would probably be to just get Hibernate, and slap it into the application. It’s easy to use, easy to setup, and removes the need to write a lot of code for basic operations. From my experience in researching about it, I found that Hibernate gets both love, and a lot of hate at the same time, and I believe I understand both points of view.
I do not like Hibernate that much, mostly because of the problems that I’ve had with it in the past. For simple cases, I believe it to be a great solution, but once things get complicated, it starts to get in the way. Not wanting to put all the blame on Hibernate though, since I’m not an expert or have very advanced knowledge of it, and probably most of my problems with it were caused by this inexperience in its advanced concepts. tomorr was simple, and Hibernate would have worked good for it, but trying something different here was one of the goals from the start, something I had heard being mentioned many times, and mostly in a positive manner.
That was JOOQ, and using it here made me realize how easy and simple it is. With JOOQ you have to write the code for the basic operations yourself, but the freedom it gives, especially in reporting, is amazing. Not to forget that it integrated quite smoothly with Spring.
Having a database to handle the data, and an API to handle the requests was a good start. However, I needed more. I wanted tomorr to be able to work correctly, even when multiple instances of it are deployed. The instances would need to share configuration, and share the workload as well.
RabbitMQ and Redis
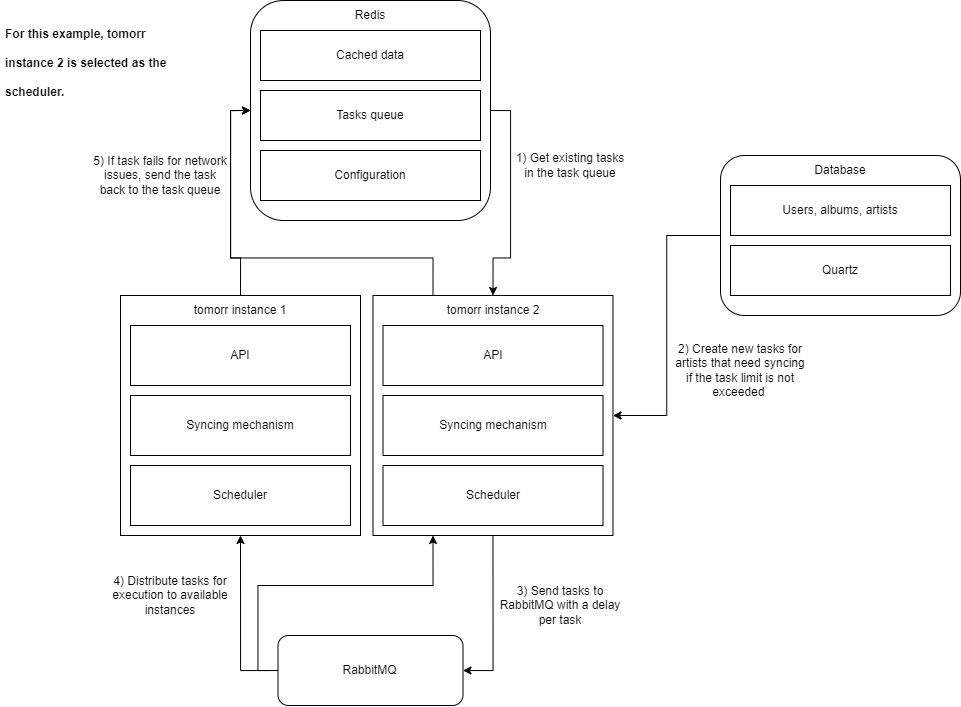
To make instances work together smoothly, Redis and RabbitMQ were added. Redis would store the configuration of the application, such as the current access token for Spotify API requests (ignoring the security issues on this specific part now), the queue for the tasks that will be processed in the future, rate limiting information, and general caching of other data. On the other hand, RabbitMQ would receive a list of tasks from tomorr, and send them back to tomorr. This way, the instances would be able to handle the tasks in a distributed way.
The tasks were created by a scheduler, configured using Quartz, which would get tasks from the task queue, create new tasks if needed, and send them to RabbitMQ with a delay per task. Only one instance would do this per minute, and that instance could be different every time. This worked great because it meant we did not have a master node that would handle the task creation, we just had a group of instances, each of them having the potential to create tasks in case any other instance shuts down.
Each task would then be retrieved by a tomorr instance and executed, based on its type and data. The execution of the syncing process involved sending requests to Spotify in order to fetch the artists we wanted to sync. Sometimes as networks are, they just fail, or even if they don’t fail, a limit can be exceeded. In those cases, the task would be reentered into the task queue, and processed again later, ideally in the next minute when the sync process starts again.
When an artist had released something new, the email service would be called and send a notification for the release to all the users that followed that artist in tomorr. In case the email failed, for any reason, it would be scheduled to be retried again. The email templates themselves were nothing fancy, just pure HTML with an image attached to it. I used Thymeleaf for the email templates since I believe it to be the easiest template engine to use and integrate into Spring. I haven’t had the chance to try many template engines, but of those few I tried, Thymeleaf stands out as the most flexible and easy to use.
All good until now, all good. The sync process should work fine, emails should be sent correctly, and we even have caching. If someone decided now to stop, and just browse the codebase, they would notice a pattern. A pattern that I have heard many people praise, and many other people talk against it. That is the pattern of having an interface for each service, and then an actual implementation class for it. Personally, I think this is a good idea. Yes it means that you’ll have to write more code, and probably have way more classes, but it gives freedom to make big changes easily later on. I think that a lot of times you don’t need that freedom because things don’t change drastically that much, but when they do, having the architecture ready for it makes changes a piece of cake.
See, tomorr was already going to go through big changes like that, even before it was created, I had decided the way it would change in the future. The level of abstraction used in the project would be useful later on. One of these plans was to ditch RabbitMQ, and use SQS instead in the future.
Before I had to do that though, I needed to first deploy the application, and see it working with the initial idea. Even before that, I had to make the infrastructure. Here comes AWS.
The cloud
As a high school student, at the beginning of my programming journey, one of the goals was to create an assistant. Watching too many Marvel movies, the idea of having my own Jarvis sounded amazing. After many hours spent searching through the internet, I managed to find a library that would convert text to speech. What the text would say was simple, just a ‘Hello Sir’. It would not tell me what time it was, or show me the weather, it would just say those small words. Spending some time working on it, the project ran, and then I heard it, that simple and small text being said by a computer. I felt so excited that I made it work, I never forgot about that moment. In the eye of an experienced programmer, I was the noob who spent hours to get something easy setup, but in my mind, I had just done something amazing. To hell with Jarvis, I was gonna make my own Ultron now.
Learning AWS, and being able to see how much I could do with it, brought that same feeling of excitement back to me.
I always knew about the cloud, knew people used it, heard a lot about it, but never tried to do anything with it more than spawn a tiny VPS. Wanting to learn it, I bought a course on Udemy, and started diving into it.
The journey of going through that course and diving deep into the cloud was one of the most beneficial ones I took. Knowing more about AWS not only made me understand how to build an infrastructure and deploy on it, but it made me see and understand the huge amount of problems that exist outside of code. From security, to operation problems, to availability problems. Made me learn to think in a different way when developing something new, a better way.
Experimenting with AWS was easy, some new EC2 instances, a database here, an S3 bucket there. You just created something, messed with it, and deleted it later. This was all fine until you start to do things the right way. Deploying a whole infrastructure by hand is doable, and I did it, the problem is to do it time and time again, exactly the same way. Tools already existed to solve those problems, some provided by AWS themselves, some by other companies. Three options were available to me.
The first was to use CloudFormation, but people recommended against it. The second one was to use AWS CDK, which seemed way more attractive than CloudFormation, and lastly Terraform.
I chose Terraform based only on other people’s recommendations, and it worked out quite nicely in the end. Not only there were great resources to learn it on its website, but the documentation was also filled with examples and detailed information. To this day, HashiCorp documentations for Terraform are one of the best documentations I’ve had the chance to read.
Initially, tomorr was going to be deployed in EC2 servers, using an auto-scaling group, with a load balancer in front of it. It was not supposed to be dockerized, I had plans to switch the infrastructure to ECS later on. The idea was to get used to doing things the old-fashioned way intentionally and then modernize it in the future. All that was needed was to configure the properties retrieval, install Java and the needed agents for deployment, and create an image from it to use later on.
Halfway through the project, with all the changes being made, and all the work needed to keep the AMI up-to-date I decided to give up, and just switch to ECS. One other reason was CodePipeline. Having set CodePipeline by hand multiple times, doing it using Terraform was a lot of work, in comparison to other alternatives out there. GitHub Actions was free for public repositories and had good documentation and examples for integrations with ECS, which in the end made the setup of deployment much more enjoyable.
All the instances deployed are of the cheapest instance types, for obvious reasons, and all EC2 instances are spot instances. This was perfect considering I did not want to spend a lot. On my calculations, tomorr would cost around $140 - $150 dollars per month. After deploying it, and keeping it alive for a few days, the price was always around in the range of 4.20$ - 4.40$ per day.
What fascinated me was that spot instances are cheaper than I thought they would be, and on the other hand, NAT gateways can be much more expensive than I expected them to.
Here are some images showing how much tomorr cost in a single day:
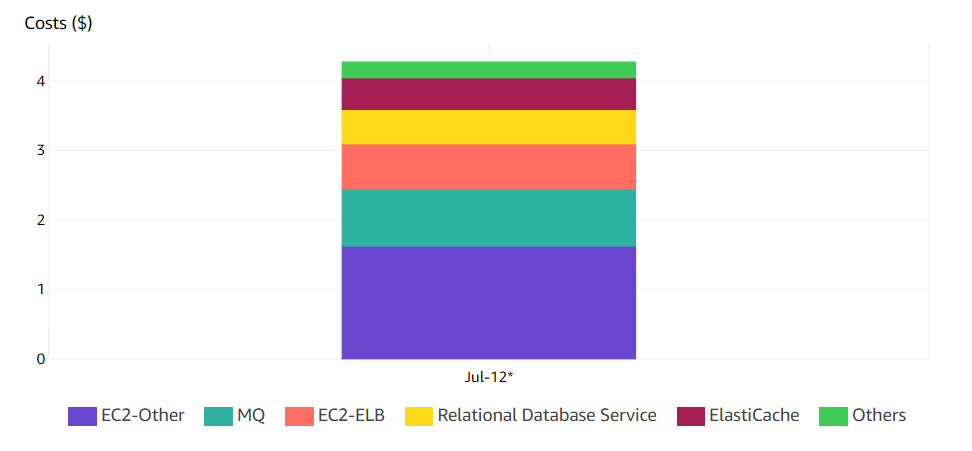
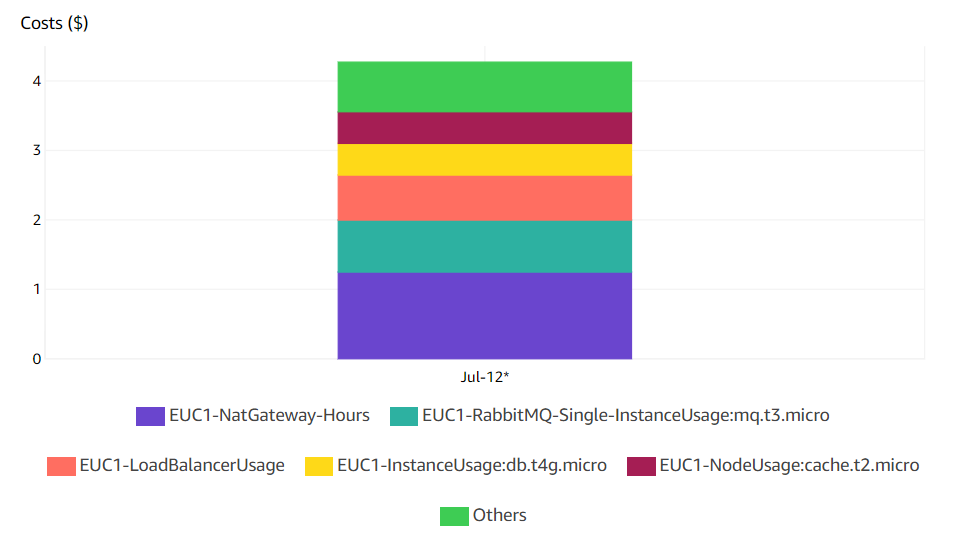
As you can see in the images, almost half of the price is spent on the NAT gateway and Amazon MQ. In both those cases, we can make cuts.
One of them would be to switch from Amazon MQ to SQS. Not only do we get a better price here, but we do not have to worry about scale either. NAT gateways are another problem though, yes they are expensive, but switching them for a NAT instance is not something that I would do on production. Maybe they would be a good use case for the test and development environments, to cut the prices a little, but the scalability and availability that you get with NAT gateways is not something that I would trade for price. They are much easier to set up as well (Here I sacrificed price to get the better option).
tomorr had no problems with scale, it never will probably, but the same can not be said for availability and fault tolerance, and I was proved this while the application was running.
It was almost 11 PM, and I was working on the post that you’re reading right now when I got an email from AWS. It was a notification that an error occurred in the application. I had set up a CloudWatch alarm to monitor application logs, and once it saw the words ‘ERROR’ or ‘exception’ it would notify me. At first I thought it was just a request that failed, something that would be retried again, but once I opened the logs I did not see just one stacktrace, I saw a load of them. In all of them was the same message, RabbitMQ has failed.
The availability zone was up, and no changes were made to the infrastructure for days, so that left only one possibility. Maintenance.
When learning about AWS this gets mentioned a lot. One of the good things about managed instances is that you do not have to maintain them, AWS does that for you, but AWS also gets to decide when it happens.
RabbitMQ was dead, as services always have the potential to be, that is not the problem, that is the norm. The problem is that tomorr was not ready for it. Not only it did not have high availability, it did not even have fault tolerance for this case.
A good solution would be to have a standby broker on another availability zone, and have fault tolerance built into the application when communication with the broker encounters an exception.
Some tasks were lost when that happened, but that was not a big issue, the tasks for the same artists would be executed again later, and the worse thing that happened was that the syncing process was delayed a little. But what if that was not a task used for syncing, what if that was an email that failed to be sent on the first try and now would be entered into the queue to be retried later? That would mean one user not getting notifications for an artist he followed, the application not doing what it was supposed to do.
Just because RabbitMQ fails, the other parts of the app should continue working, and ideally, there should be no data loss. If a task couldn’t be sent to RabbitMQ, it can be stored either on the database or Redis, and scheduled to be retried again.
The reason why tomorr does not have standby and backup instances for the broker, database, and cache is because of the price. This was a learning project, and even though it was not going to be live for a long time, I still wanted to spend as little as possible.
I made the cuts here, but maybe it would be better to use a NAT instance or a group of them, and have standby instances for those other services, with the money that NAT gateway costs.
Both high tolerance and high availability are something that I want to add in the future.
High availability options that AWS provides for its managed services do not seem like an option, but more like a requirement. A requirement for any serious application.
Testing
When tomorr was deployed, everything kept going smoothly, for some time. The syncing was working fine, API was okay, and I even had followed an artist that would release soon, just to see those notifications in my email. Few hours went by, then the error came. The email service was working, but it couldn’t read the template that the emails used, some Thymeleaf configuration error. See, of all cases that I thought tomorr would stop working, a Thymeleaf configuration error was not on that list, and it was the one tiny part that didn’t have a test.
This was not the first problem to appear because of configuration errors. Unit tests just aren’t able to cover everything, so I needed integration testing to make sure the communication of tomorr and the database, cache, or broker was working fine. During the early days of development, I used to manually test the API from time to time, and it failed even though all the unit tests were passing. Whether it was a misconfiguration on Redis, the JSON marshaller it used, or maybe something completely different, the issue was clear, a lot of integration tests were needed.
The decision on how to go about it was easy. I was not going to use an in-memory database like H2, or an in-memory Redis cache, neither I was going to have instances running always and do the integration testing on them. There was this library called Testcontainers that I heard mentioned a lot on Twitter and decided to give it a try. It didn’t just fit perfectly, but it changed how I do integration tests.
If you’ve not heard of Testcontainers, then you should definitely check it out. It uses Docker behind the scenes to create containers of the services you require, and you can then easily set up your application to use those containers during the integration tests.
Shared configuration or separate configuration
Making separate configuration files for test beans seemed a good idea at first, it allowed me to have more freedom, and make some smaller changes to adapt the beans to the test libraries easily. I was wrong.
It got confusing, and it didn’t take long for the test configuration to mismatch with the real configuration. This resulted in integration tests passing sometimes, but when testing the application manually, the same logic failed. This was a big slap in the face, and a bad decision from the start.
The better solution was to keep the test configuration file but extend it from the real configuration file. This allowed the test configuration file to be used mostly for setting properties, which were different for testing, but the configuration itself was always the same as the application used when running.
On test names
shouldThrowErrorWhenArtistIsNullOnSave
or
saveArtist_WhenArtistIsNull_ThrowError
Which one do you think it’s better? I’ve used the first one in the past, and it’s fine. But the second choice here is way more readable in my opinion, and that’s the one tomorr uses.
The catch is that you use method names in tests, but if those method names change, the test name should change as well. It can be annoying but as long as this rule is followed, everything should be described correctly.
Do the research first!
I always do, I promise. Well, most of the time, but I’m striving for always.
It wasn’t fun to see near the end of development, that Amazon MQ does not support rabbitmq_delayed_message_exchange plugin, which the application relied on to distribute the tasks among the minute that they had to be executed in.
An alternative was found quickly, but still, this is not one of my proudest moments. Don’t assume, research.
The future of tomorr
There are so many features that I can add to tomorr, some that probably do not serve that much to its core idea, but that would help me a lot to experiment with new things.
I might add other things as well, but here are some that I’m interested to implement in the near future:
- A web application that you can use to follow the artists you want, and manage your following as well, instead of using the API directly. I plan to use React for this, simply because I’m familiar with it, and learning other frontend frameworks is not something I’m interested in at the moment.
- Switching to AWS managed services. I had this idea when I started tomorr, and it was something that I always wanted to do in the future. Using SQS instead of RabbitMQ, Parameter Store instead of environment variables stored in S3, and integrating Spring Boot AWS library to get the most out of the AWS services that I’m currently using. Those are just some of the changes that I wanted to do regarding the switching from one service to the other, which allows me not only to learn more about the services themselves but also to see how to handle migration when making the changes.
- Authentication using Cognito, would allow me to learn and research quite a lot on the service itself. Cognito is what I have in mind for now, since also I’m focused to dive deeper into AWS services that I previously didn’t have a chance to, but I might consider other alternatives as well once I start researching.
- Adding a new service that fetches ratings and data about a song or album from different third-party services. This would be a good case for me to try gRPC and dive deeper into it since I need communication between the services. Also since I used Java in the core service, this can be a good opportunity to use Go here.
- A new analytics service. This would include analytics about artists, albums, tracks, users, ratings, and everything I plan to add in the future. It is not something I’ve thought about a great deal, but it is a good use case that would allow me to use Kinesis and Redshift (or any other OLAP database).
Would you help?
The reason I share this project and this post, does not have to do only with the hope that someone will find it useful and helpful. There are some selfish reasons as well. If you have the time to check the code, please do so, and please share anything that you think could have been done better, anything that is done terribly, anything at all.
I want to see things that I might have missed, things that I did not consider because I probably don’t know about them, better alternatives.
Writing is HARD
Writing is hard, not hard in the sense that I don’t know what to write (I could blab for hours), but I found it hard to put into paper what I had in my mind, in a way that I assumed it would be clear and easy to understand for anyone that reads this post.
It’s hard to know if what you write you is truly useful since what I consider useful and interesting, can probably be seen as something irrelevant to the bigger picture.
What I see as clear, can probably be confusing and all over the place for someone else.
What I consider to be funny, can probably be seen as something annoying by others.
As with other things, I believe that with some research, and a lot of practice, I can slowly start to improve, but writing this made me appreciate much more the people that write books, blogs and papers.
Resources
To learn AWS, I used this course by Stephane Maarek, and I highly recommend it.
For JOOQ, Testcontainers, RabbitMQ, and Terraform, the official documentation, guides, and tutorials are very helpful and the only thing you will probably need.
When it comes to Redis, the book Redis in Action is very helpful to understand the core concepts, and how to do more advanced stuff as well.